
What is WebScrapBook?
WebScrapBook is a video capture extension for chrome. it's a free extension , it has 20,000+ active users since released its first version, it earns an average rating of 3.60 from 67 rated user, last update is 619 days ago.
What’s new in version 1.10.1?
WebScrapBook is a browser extension that captures the web page faithfully with various archive formats and customizable configurations, for future retrieval, organization, annotation, and editing. This project inherits from legacy Firefox add-on ScrapBook X.
Features:
1. Capture faithfully: A web page shown in the browser can be captured without losing any subtle detail. Metadata such as source URL and timestamp are also recorded.
2. Customizable capture: WebScrapBook can save selected area in a page, save source page (before processed by scripts), or save page as a bookmark. How to capture images, audio, video, fonts, frames, styles, scripts, etc. are also customizable. A web page can be saved as a folder, a ZIP-based archive file (HTZ or MAFF), or a single HTML file.
3. Page editing: A web page can be highlighted, annotated, or edited before or after a capture.
4. Organizable collections: Captured pages can be organized in the browser sidebar using one or more scrapbooks, and each scrapbooks holds a hierarchical tree structure to organize data items. Notes using HTML or markdown format can also be created and managed. (*)
5. Fulltext searching: Each scrapbook can be further indexed for a rich-feature search (using title, fulltext, comment, source URL, create time, modify time, etc.). (*)
6. Remote access: Captured data can be hosted with a central backend server and be read or edited from other devices. Alternatively, a scrapbook can generate a static site index and be distributed as a static web site. (*)
7. Mobile support: WebScrapBook supports mobile browsers such as Firefox for Android and Kiwi browser. You can capture and edit the web page from a mobile phone or tablet.
8. Legacy ScrapBook support: Scrapbooks created from legacy ScrapBook or ScrapBook X can be converted into WebScrapBook-compliant format for usage. (*)
* All or partial functionality of a starred feature above requires a running collaborating backend server, which can be easily set up using PyWebScrapBook. (*)
* An HTZ or MAFF archive file can be viewed using the built-in archive page viewer, with PyWebScrapBook or other assistant tools, or by opening the index page after unzipping.
See Also:
* For further information and frequently asked questions, visit the documentation wiki: https://github.com/danny0838/webscrapbook/wiki/Intro
* For better discussion, please report an issue to the source repository: https://github.com/danny0838/webscrapbook/issues
* Donate to support us if you find this tool helpful: https://www.paypal.me/danny0838/5usd
How to install WebScrapBook?
You could download the latest version crx file or older version files and install it.
Preview of WebScrapBook
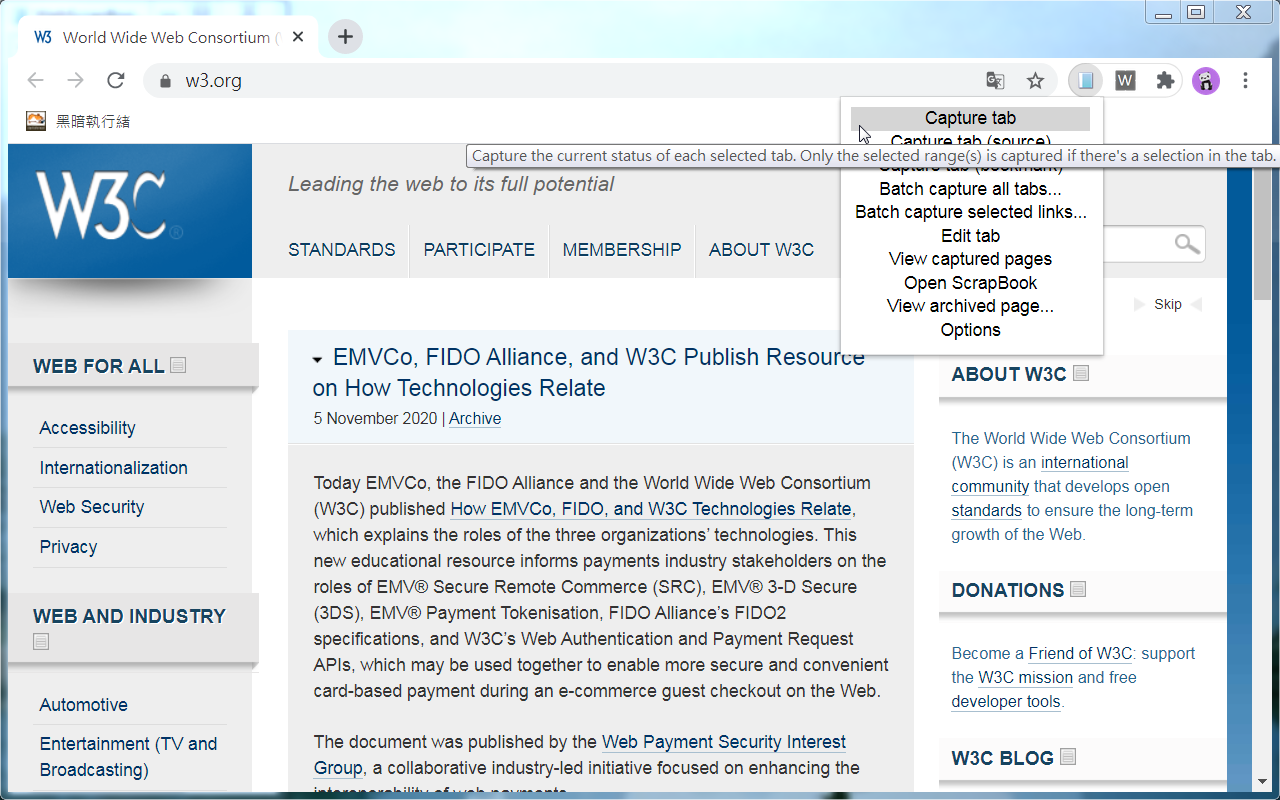
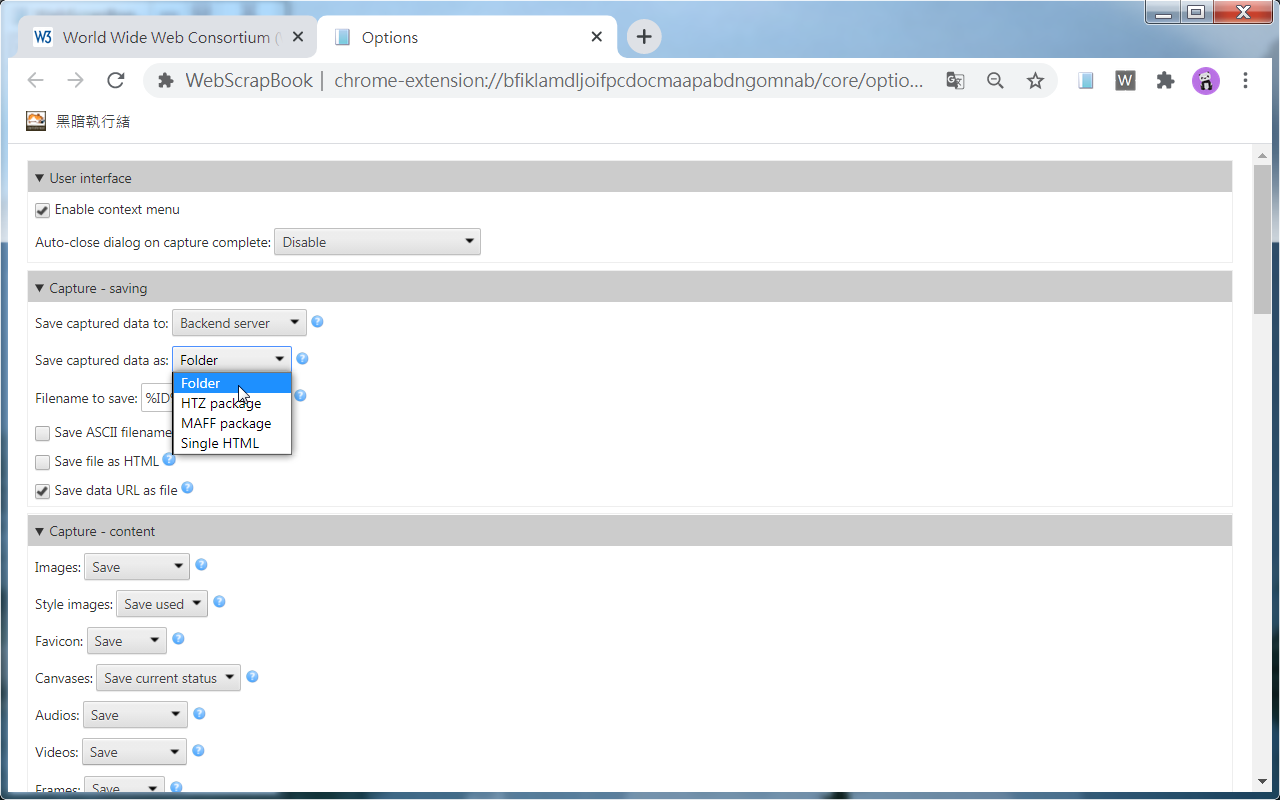
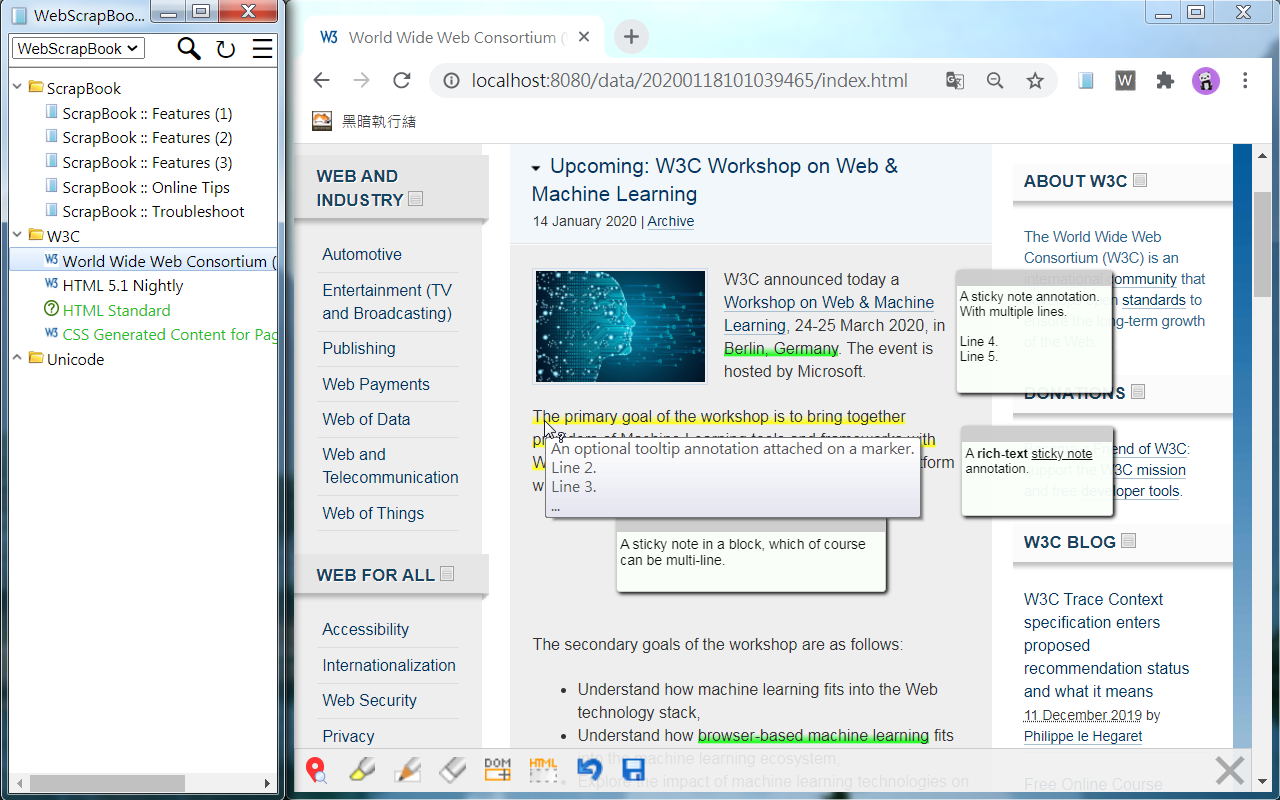
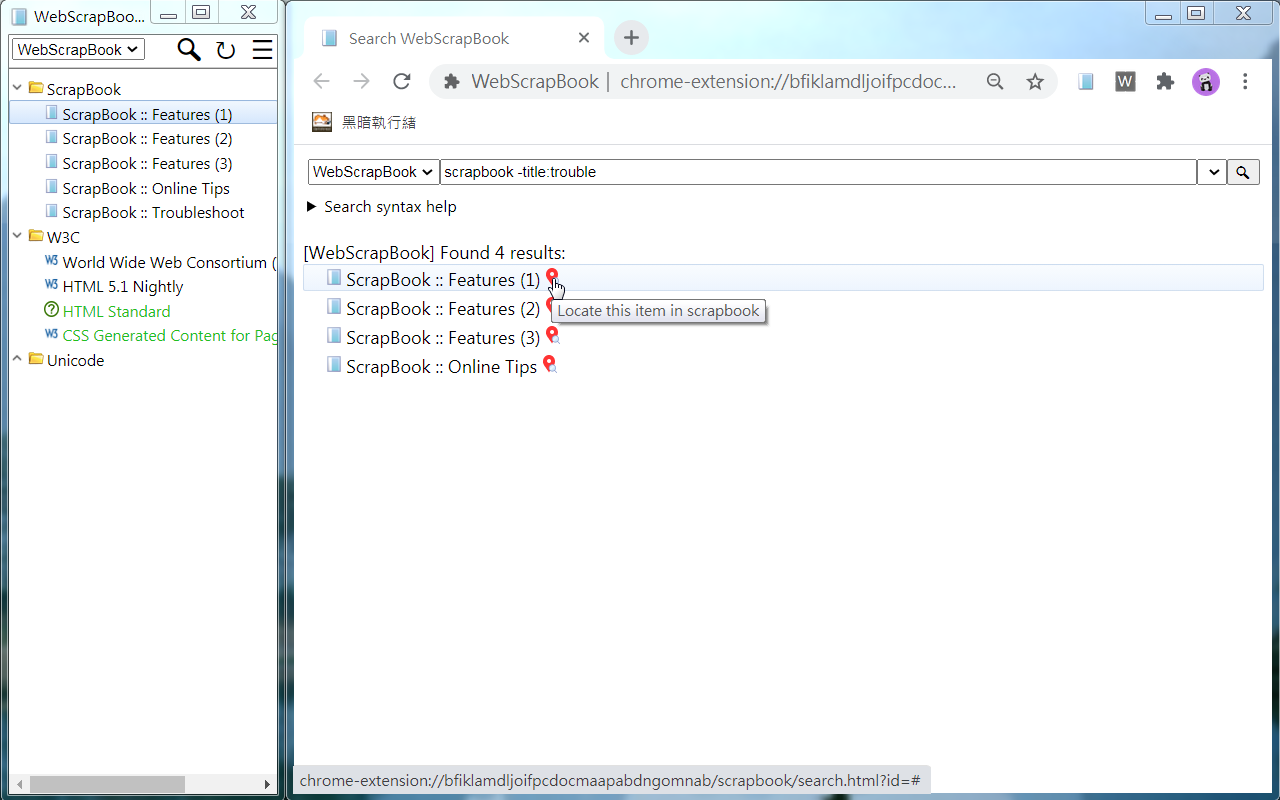
Technical Features:
- Latest Version: 1.10.1
- Requirements: Windows Chrome, Mac Chrome
- License: Free
- Latest update: Thursday, April 13th, 2023
- Author: Danny Lin
WebScrapBook Available languages:
English, 中文 (简体), 中文 (繁體).
FAQ
-
What about others talk about webscrapbook chrome extension?
29% user give 5-star rating, 24% user give 4-star rating, 6% user give 3-star rating, 24% user give 2-star rating, 18% user give 1-star rating. Read reviews of webscrapbook
-
How could i get help if there is something wrong with webscrapbook chrome extension?
You could find more help information from webscrapbook support page.
-
How could i contact the developer of webscrapbook chrome extension?
You could send emails to publisher, or check publisher's website.
-
What are the required permissions for extensions?
- contextMenus
- downloads
- storage
- tabs
- unlimitedStorage
- webNavigation
- webRequest
- webRequestBlocking
- http://*/*
- https://*/*
- file://*
More about manifest_file of webscrapbook.
-
How could i report abuse of webscrapbook chrome extension?
You could click to report abuse of webscrapbook.
Reviews of webscrapbook:

I have very limited programming experience so there might be some dunning kreuger at play here, but this much, much, much, MUCH better than httrack or cyotek webcopy. The documentation is great and all, but I feel like most of it could be made redundant with a simple video tutorial.

Agree with Clarence Domesticus Wonderful extension, as a ScrapbookX user for years, I think this extension is able to do almost the same as scrapbookX, and additional features of PyWebScrapBook backend make it more useful. I can stop using the now very very slow old version of firefox eventually. Thanks a lot.

I am sorry to have to give this promising extension 1 star, however I have spent 5 hours trying to save a page and the pages linked from that page. You can play around with depth and filters (God knows what "Each following line is a full URL (with chars following a “#” or space stripped) or a regular expression (e.g. “/^http://example\.com//”). " in the options is supposed to mean,). This is by far the most frustrating, and time wasting Chrome extension that I have ever installed. It simply does not work! Lastly, I tried both the Chrome and Firefox versions and only ever end up with the orginal page being saved i.e. no subpages.